Here are a few notes and things that stuck out to me while kicking the tires of ProxMox. Keep in mind these are coming a VMware Admin with very weak Linux knowledge. I will keep adding stuff as I learn, however keep in mind, I started this post in mid 2024, so things have changed.
Uses QEMU/KVM for virtualization
LXC for containers
Corosync Cluster Engine for server communications
Proxmox Cluster File System for cluster configuration
-If installing ProxMox v8 crashes on install, see if v7 works, if it does then do an in place upgrade
-Neither v7.4 or v8.1 seem to recognize Mellanox CX-3 40gbE/InfiniBand network cards, later on I got one system to see the NIC when ethernet mode, so perhaps it's an Infiniband incompatibility.
-The vCenter equivalent: it is just built in to the webUI of each host and works on a distrusted/cluster model, IE there is not appliance to install, no software keys, no dedicated IP. Imagine if the stand alone ESXi WebGUI had basic vCenter functions built in, ie joining and managing multiple host in one interface, vMotion, and replication.
-There are oddities about moving VMs back and forth from LVM to/from ZFS. A VM built on a ZFS volume cannot live migrate, cold migrate to a LVM volume; a template that lives on an LVM volume cannot be spawned to a LVM volume; IF there is a replication job attached.
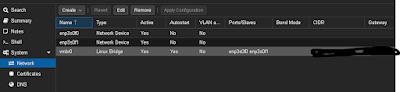
-by default a network "bridge" is created. Network cards can be added/subtracted as necessary; very much like the "virtual switch for VMware/ESXi
-The default install, will have several "nag screens" about wanting one to have a paid subscription. No judgment here: "gotta pay the bills". The default update repository is the from the paid tier, one must disable it and point updates to the "no-subscription" tier, to get updates and lessen nags.
-The ProxMox virtual machine tools, actually QEMU (vmtools equivalent) is a separate download. It must be installed for any "thin provisioning of VM memory. IE a Windows VM running w/o the tools set to 8gb of RAM will consume 8gb of RAM on the host. With the tools it will take some amount less.
-That same ISO (proxmox virtio-win-xxxxxx.iso) will most likely be needed for installing Windows. Things like the hard disk controller (depending which one was chosen on VM creation) will not be seen and require drivers to be installed.
-Replication jobs! If they fail and one wants to delete the job, and they seem to not go away through the GUI. Go to the shell and type: "pvesr lit" to show the jobs. Then "pvesr delete JobID --force"
-A template cannot migrate to a different host unless the name of the storage on both servers is the same.
-A template cannot be cloned (image spawned from) to a host that doesn't have the same storage name. If the template exists on local storage it cannot be cloned to another host, and the dropdown box for what storage to use is blank. One has to clone the machine on the same server where the template lives, then migrate the cloned VM.
-One down fall of a cluster, if one has a cluster and more than 50% of the hosts are offline, one cannot start a VM. So say for instance there is a hardware/power failure, something that brings down half of the hosts. A VM is off that needs to be powered on. If the cluster doesn't have quorum, the VM's won't start!
-Online/live migrations, the VM must be using the same network bridge (virtual switch) one each host. i.e. both servers should be vmbr01
-configuration files for the VMs live here: /etc/pve/qemu-server; if things go way wrong one can move the config file to another host by:
mv /etc/pve/nodes/<old-node>/qemu-server/<vmid>.conf /etc/pve/nodes/<new-node>/qemu-server
-virtual disks can be accessed here: /dev/<disk name>
Rename VM LVM Storage Name VIA SSH
cd /dev/pve
lvrename /dev/pve/vm-100-disk-0 /dev/pve/vm-297-disk-0
-There does not seem to be an easy way via the GUI to rename storage.
the 1st icon is running VM, the 2nd a VM that is being migrated, the third is a template.
v7.4 Cluster
Things I really like about ProxMox:
-ability to migrate running VM's from one host to another; even without shared storage
-ability to backup VM's
-ability to replicate VM's
-no need for a dedicated management VM/appliance
Challenges:
-I had an unexpected host failure; the VM tired to migrate to a different node; at the time there is only local storage, not even Ceph.. The local node volumes also where not the same. After the node came back online, it had the VM's virtual drive, as it couldn't migrate, another server in the cluster had the config file. Getting things back inline was a real chore. Simply moving either the virtual hard drive or the config file was not working. Sure one could blame it on me for not setting up shared storage, or not having the datastores named the same. However why is HA not doing checks before attempting a migration?
-Another unexpected host failure; two nodes are disconnected from the cluster.....Nodes 1, 2, 3, and 6 are all up and joined together and report nodes 4 and 5 as offline. Nodes 4 and 5 believe they are online, and the other four nodes are off line. Removing and re-adding the nodes to a cluster is not straight forward and not doable via the GUI.
------------------------------------
-Abbreviated: Instructions to upgrade from v7 to v8
-from the shell of a given node type:
-pve7to8
-apt update
-apt dist-upgrade
-pveversion
-sed -i 's/bullseye/bookworm/g' /etc/apt/sources.list
-apt update
-apt dist-upgrade
------------------------------------
-To remove a damaged node from a cluster:
From the damaged node:
-stop and pve cluster services: systemctl stop pve-cluster
-stop corosync services: systemctl stop corosync
-restart in single host mode: pmxcfs -l
-delete corosync config: rm /etc/pve/corosync.conf
-delete corosync folder: rm -r /etc/corosync/*
-delete reference to other nodes: rm -r /etc/pve/nodes/*
***VMs living on the damaged server will be lost.....the virtual hard drive will still be there
------------------------------------
qm list (shows VMs)
qm start/reboot/reset/stops vmID (starts/safe shutdown and startup/reboots/hard powers off off a VM)
pvecm <--proxmox manager status
journalctl -b -u corosync <--see log stats of the corosync (clustering service)
------------------------------------
To change a server name:
edit the following files:
nano /etc/hosts
nano /etc/hostname
nano /etc/postfix/main.cf
reboot now
------------------------------------
service pve-cluster stop
service corosync stop
service pvestatd stop
service pveproxy stop
service pvedaemon stop
and then
service pve-cluster start
service corosync start
service pvestatd start
service pveproxy start
service pvedaemon start
--------------------------
If one has a cluster and some of the nodes are off line for a long time, like if one is attempting to be energy usage conscious, or similar; when that node comes up, the cluster database will be out of sync and the recently powered up node will think it has a master copy of the cluster configuration. Be patient and wait. The nodes will sort themselves out and the copy of the cluster database with the highest revision number will be replicated around.
------------------------
Clusters & Quorum!
If one has a cluster with 50% or more of the server nodes down, VMs cannot be changed or powered up. The Cluster database needs to have half of the servers plus one up and online. In my case I had six nodes, all of the VMs were consolidated onto three nodes, the vacated hosts where shutdown to save energy. This caused problems, until a 4th host was re-powered back on. This could make for very interesting disaster recovery scenarios.
There is a quorum service package (qdevice) that can be installed on most linux machines. This allows another voting partner in a cluster; most likely useful when the cluster only has two hosts.
------------------
There is a pile of scripts out there to help one out. I used one named: "Proxmox VE Post Install" that quickly sets the repository locations.
https://community-scripts.github.io/ProxmoxVE/scripts?id=post-pve-install






.png)